
Overview of the book digitizing process.
Let's Adore Jesus-Eucharist! | Home >> Varia >> Software Engineering
Overview of the book digitizing process.
Here's an overview of the process I use (please tell me if you have a better method). Each step will be explained below:
1.1) Intellectual property. Before putting a book into the public domain, we must make sure it is no longer copyrighted, or that the owners have given their written permission.
1.2) Digital photography ("Scanning"). An electronic device converts the paper pages of the book into large files containing raw pictures of those paper pages.
1.3) Optical Character Recognition (OCR). A software takes the raw pictures of the pages and interprets them as best it can, transforming the ink blots into letters of the alphabet.
1.4) Correction. A reviewer compares the raw image with the OCR output, and makes the necessary corrections.
1.5) HTML or other encoding. This part of the process is variable. It can include formatting of the text (italics, bold, styles, etc.), the organization of the logical elements (footnotes, table of contents, index, etc.), and the features proper to digital books (hyperlinks, animations, etc.).
Ideally, you contact the copyright holders and get their written permission. If you can't find them, or if they don't answer you, at least try to gather the "legal evidence" which might eventually help you show a court of law that you did what you could to get this permission. (See for example the Open Letter To Desclée de Brouwer.)
Here are the steps:
3.1) Get access to some scanning device. This is easy, since just about any device will do, including walking down to the local post office and using their professional-grade photocopier. Photocopiers these days scan the pages they need to copy, and can save those scanned pages to PDF or other formats, which you can then retrieve using a USB thumbdrive. My old scanner (Canon Canoscan LiDE 80) was one of the simpler and less expensive models on the market, purchased for about 150$ many years ago. Since then, prices have just gone down and features up, so you can't really miss! By the way, you can pay a lot of money for an automatic document feeder, but I'd say it's useless, since the pages of old books which are out of print (precisely the kind of book you tend to want to digitize!) often have formats and thicknesses which are not amenable to automatic feeding.
3.2) Get scanning software. Often, they come bundled with the scanner. That is how I got my ScanSoft Omnipage SE software, which was adequate for me. This program also did the OCR, but I cannot get it to work under Windows 7. Moreover, as of 2017-Oct-09, it was no longer available, but others seem to perform the same functions, like Nuance OmniPage Standard, ABBYY FineReader 14, etc.
3.3) Prepare the book. Unfortunately, so far I've had good results by cutting of the book's spine, which separates all the pages and let's me position them on the scanner's bed. Here's a method that works: (1) cut off the cover; (2) put the book on the edge of a workbench; (3) set a metal ruler near the book's spine (you have to be far enough from the spine to cut all pages free, but not too far to avoid lopping off some text); (4) clamp down everything tightly with two bar clamps; (5) cut with a utility knife (Xacto, Olfa, etc.); (6) after scanning, you can sandwich the free pages between the two cut covers, and hold everything with elastics. You have to keep the original as long as the digitizing process is not finished. Of course, if the book doesn't belong to you, don't cut it! I've scanned a book without cutting it up, but it is unenjoyable and gives poor results.
3.4) Do the actual scanning. Contrary to appearances, this is one of the fastest and most pleasant parts of the process, so enjoy it! You start the software and the scanner, and manually place the pages on the scanner's bed, one after the other. Stop every 50 pages, and save your work, in case the software crashes (it's happened to me several times). Name the files according to the pages they contain, like for example "pages 0001 to 0060.opd". See your scanner's Manual for details.
At the end of this step, some people declare victory and just plop those huge files onto the Internet, claiming that book has now been "digitized". I think that's verbal inflation: that book has just been photographed, not really digitized.
A picture of an ink blot in the shape of the letter "A" is not the same thing as the letter "A". The letter "A" takes about 8 bits of memory to store (if for example you are using ASCII), and the computer knows exactly what are those Ones and Zeros (the letter "A"!). But the picture of an ink blot can take up huge amounts of bytes, and a computer can interpret this ink blot in many ways, including: "I have no idea what this is". A really digitized book requires much more work, but also has many more advantages (like compactness, ease of indexing, ease of corrections and additions, etc.).
This is probably the most complicated part of the process, but fortunately this complexity is hidden inside the OCR software. All you need to do is push a button and the computer does (almost!) all the work. The software will ask questions when it will be unable to recognize certain words. In the following example, the software is confused because there is no dot on the "i":
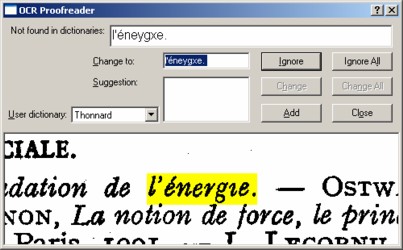
Example of an OCR error.
This is the part of the process that normally stands the most to profit from more recent versions of an OCR program. At the end of the OCR step, the software produces a file with the characters it has managed to recognize.
It's also the part of the process which has gone down in importance the most since I digitized my first books. OCR software is now so common that it's becoming rare to find a "virgin" book, which has never been photographed and run through an OCR program (for example, Google has processed a very large number of old books with this method). Try it! Just pick up a book, type a random sentence into a search engine, and you'll probably find it on the Internet. I'd also be willing to bet your local post office has a photocopying machine which can OCR your documents automatically (even if the old lady working at that post office might not even know it).
I've never come across an OCR program that avoided all errors. I guess it might be even theoretically impossible (think about pages that are torn, or vandalized by scribbling, or think about printing errors, etc.). You have to read the text file produced by the OCR software, and compare it to the raw digital image. In practice, this step is done in two stages.
5.1) First "rough cut", more or less automatically done. After the OCR but before encoding, you use the features of your word processor to make as many "global" corrections as possible. For example, the books by Thonnard don't put accents on the "À" which leads a sentence (something which should be done in French), so you can do a semi-automatic search-and-replace and correct all occurences, etc.
5.2) The "monastic" correction. That's the real correction, the one which is a monk's labor! I tend to proofread one paragraph at a time, and integrate this step with the following one (see #6.6 here below).
This is the longest and most difficult part of the process, since you're not just translating anymore (from a paper format to an electronic format), but producing something new (we often add things which don't even exist in the original work, like styles).
There are in theory at least three approaches to this step:
- save the OCR output as an HTML file, and fix the incorrect or missing HTML;
- save it into some ordinary word processor format (like Microsoft Word),
then make changes, and finally use the ability of the word processor to
save that file into an HTML format;
- save it as a plain ASCII text file, and encode the HTML from scratch.
I've tried those three approaches. As far as I know, it is currently less work to redo the HTML from scratch, if you want the result to be squeeky-clean. (Of course, newer versions of software could change this conclusion in the future.)
Here is what your computer screen might look like while you're doing this step:
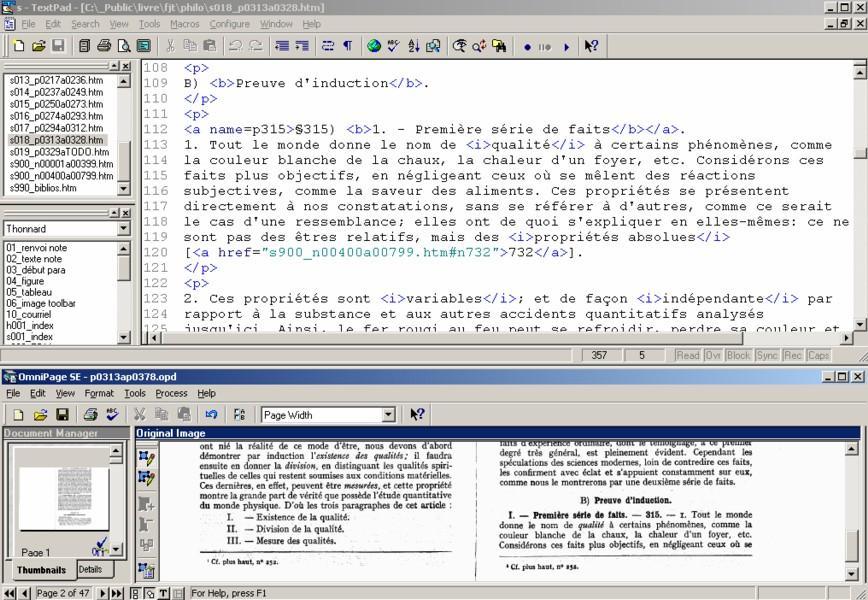
Screen shot during encoding.
If you decide to encode the book into HTML (my current recommendation), you can read a little tutorial on this topic (see for example HTML for Grannies). If you're hand-coding HTML tags, you're probably wasting your time. A good word processor will let you select the piece of text you want to encode (for example a word you want to italicize), hit a key combination, which will start a marco which will do the work for you.
Here's an overview of the steps I used to digitize the Précis de philosophie by F.-J. Thonnard. (But keep in mind that this part of the process can be highly variable from one book to the next, and from one person to the next):
6.1) Tag off a paragraph. I tend to do these steps paragraph by paragraph.
6.2) Add formatting. For example, italicize and put in bold according to the original.
6.3) Add the footnotes, hyperlinks, etc. Often, the OCR software isn't able to correctly recognize footnotes. These days, I do it this way: (1) double-clic on the "footnote source" template in the "palette of text snippets" (bottom left-hand corner in the screen shot above); (2) cut the footnote text and past it in the HTML page that contains all the footnotes; (3) add the "footnote target" text snippet (called "02_texte_note" in the bottom left-hand corner of the screen shot); (4) give the correct number to the footnote; (5) come back to the first page and set the same footnote number.
6.4) Remake or scavenge the images, pictures, drawings, etc..
6.5) Format the HTML code. (optional) You can use a macro that justifies the text. This code formatting doesn't appear when viewing the page with a web browser, but it's more polite for the other programmers who some day might have to come and modify your HTML.
6.6) Do the final "monastic" correction. Not only should you do this correction, but ideally, another person should review your work.
This article is about taking books in the format sometimes called "the dead-tree edition", and bringing them into the digital or computer version. But we can ask the question: "What about putting that book into other digital versions (there are many apart from HTML, like MS-Word, PDF, ePub, etc.), or even putting that digital version back into a dead-tree edition?"
The short answer is: sure, but I'm still looking for some miracle software that will do that correctly and at a reasonable price.
A longer answer is: for my web site, I think HTML is currently the least-bad format. For books that don't belong to me but that are on my web site, you're always most welcome to download everything and do whatever you want with them, including putting them into a dead-tree edition (just don't assume the actual copyright holders will be nice to you, just because I'm nice to you). Recent tests I've done for some guy who wanted to print out the "Petit Catéchisme" for children at his parish were to just select the text on the web page and paste it into Microsoft Word, then play with the styles until things started looking acceptable. I don't think there is any hope for automating things like page breaks (how can I know ahead of time what size of paper you're going to use for your dead-tree edition?), layout of images (do you want big pictures, small, none? on the left with text flowing around them, on the right with the text above and below, but not flowing around it? etc.), the table of contents (how many levels of the hierarchy do you want to include?), the notes (footnotes? at the end the chapter or the book?), etc. But the CSS styles I use in my HTML encoding seem to help Microsoft Word produce a fairly usable result. And normally once you've converted to MS-Word, you can go from there to PDF, ePub, etc.
(If I may allow myself a personal comment on efforts to put books on my web site into a paper format or other, thinking that this will give them a greater outreach, I congratulate you on your good intentions, but I'm rather pessimistic. Most people love their ignorance.)
Tom Gilb says: "If you don't know what you're doing, don't do it on a large scale", and Jon Bently adds: "It's faster to make a 4-inch telescope mirror, then a 6-inch mirror, than to try to make a 6-inch mirror right away".
I was lucky enough to apply that advice to book digitizing. I started with a simple 20-page book by Courtois, then graduated to a 200-pager by Sertillanges, and only then did I attack the book I really wanted to digitize, a 2000-page monster by Thonnard. I strongly recommend you follow a similar approach.
Let's Adore Jesus-Eucharist! | Home >> Varia >> Software Engineering