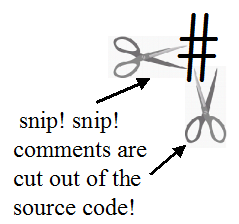
Introduction
" (String literals)
# (Comments)
$ (Non-essential properties)
' (Comparaison operators)
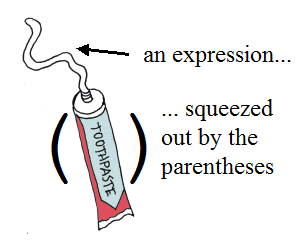
( ) (Expression)
+ - * / (Arithmetic operators)
@ ("at", i.e. Addresses, pointers, references, etc.)
= (Assignment operator)
[ ] (Subprogram parameter list)
_ ("underscore", i.e. line continuation character)
` ("back-tick", i.e. "bit" symbol)
{ } (Human Readable Form/Serialization -- Experimental feature only)
| (Relationship -- Experimental feature only)
annotation (Experimental feature only)
assert
block
compiler
const (Constant)
ctor, dtor (Constructor, Destructor)
default
dup (i.e. "duplicate")
enum (Enumeration)
export
filemap
foreach
forward ("Forward" or "temporary" definition)
func (Function -- Experimental feature only)
gepsypl (Program start, i.e. the "main module" or "main() function")
goto
grp (Group)
if - elif - else
import
inline
int, bool, float, char, str, arr, etc. (Predefined types)
interface
latebind
meta (Experimental feature only)
module
package (Experimental feature only)
proc (Procedure)
return (Non-existant keyword)
self
static
stric (i.e. type reSTRICtion -- Experimental feature only)
struct
template
test (Experimental feature only)
throw, catch, try (Exceptions)
trustme (Low-level programming)
var (Variable declaration)
while
Appendix: various details
a1) Case sensitivity
a2) ASCII, Unicode, digraphs, trigraphs
a3) File extensions (.gy7, .gy5, .gy3, etc.)
a4) Whitespace and indentation
Normally, there is a spectrum of documents describing a programming language, from brief and catchy introductions down to long (and rather boring) language references used only by "language lawyers". This page is roughly in between those extremes. Also, because GePSyPL is based on C++ (and because programmers hate to write the same code twice), I only put here what is not already better explained in two excellent books: The C++ Programming Language (4th Edition), and The Design and Evolution of C++. (I quote them as [Stroustrup 2014] and [Stroustrup 1994] respectively.)
Please be forewarned that because this language is a research project, some entries in this page are more "thinking out loud" about various design options, rather than authoritative statements about how this language works.
How is this document organized? Because GePSyPL has intentionally many keywords (and because operators are just keywords represented with symbols, i.e. operators are "key-symbols" not "key-words"), and because those keywords are (hopefully) chosen to represent all important programming concepts, it seems logical to just organize this document alphabetically by keywords (and operators).
Finally, a note about terminology. Different programming languages often use different words to say the same things, leading to unnecessary confusion. As far as possible, I use the most commonly-used words. When I don't, I try to have good reasons. A few examples:
subprogram, function, procedure: in GePSyPL, like in Pascal, a subprogram can be either a procedure or a function. So a procedure is a subprogram, and a function is a subprogram, but a procedure is different from a function (as opposed to languages like C++, Java, C, etc., who call both a "function").
type: what C++ and many other languages call a "class" or "struct".
variable: often called "object" by other languages.
member variable, member subprogram: what Swift and other more "pure" object-oriented languages call a "property" and a "method".
parameter: often called "argument" in the litterature. They can be formal (when the subprogram is formally defined) or actual (when the subprogram is actually called for execution).
constructor and destructor: in Swift, called "initializer" and "deinitializer".
Declaration, definition, statement, expression: "Declaration": doesn't make the CPU do anything, and doesn't make the compiler do much, except introduce a name (and maybe a bit of a type) into the compiler, just enough to allow others to use this name before it's defined. "Definition": doesn't make the CPU do anything, but fills up the compiler with stuff (e.g. a variable definition, a subprogram definition, a type definition). "Statement": makes the CPU do stuff, but doesn't "leave behind" a value (e.g. "result=2+2"). "Expression": makes the CPU do stuff, but "expresses" or "leaves behind" a value (e.g. "2+2").
I love delimiters that have only one character (easy to type) and that have a distinct START and STOP character (which facilitates scanning). Unfortunately, ASCII doesn't have the nice «guillmets», and the almost-universal convention in programming languages is the "double quote".
Having the same character signal both the start and the stop of a string literal already causes problems, but things get worse. There is a bewildering number of ways to quote a string in C++ (and unfortunately I think much of that complexity is not caused by some design error in C++, but by the underlying complexity of the topic). See [Stroustrup 2014], pages 176 to 179. From what I understand, the complexity is caused by:
- There are any number of possible character sets to represent (for example, plain English, French (same as English, but with some diacritical characters), old-fashioned Greek, Korean, etc. Many of those character sets are constantly increasing! (I seem to remember every time a new word is invented in Japanese, they have to invent a new character!).
- Each of those character sets can be represented by any number of encodings (i.e. each character is mapped to a series of ones and zeros). For English, you have for example the Morse Code, ASCII, EBCDIC, Unicode, etc.
- Sequences of characters must have some kind of way of indicating the start and the stop of the sequence. For example, in C, if you put something in between two single-quotes, it means a sequence of just one ASCII character. If you put one character in between double-quotes, that will be a two-character string, because in the C language, strings end with a null ('\0'). Old-style Pascal used to have one byte at the beginning of a string indicating its length (hence a limit of 256 characters for any string). The start and stop method can be different whether the string is represented in the source code file, or in the computer's memory, or the actual program file.
- Each encoding can itself be "encoded", for example you can express a string of ASCII characters using hexadecimal, or octal, etc.
- Many encodings can be compressed. For example, Unicode can be in a compressed format like UTF-8, UTF-16, UTF-32.
- All of this stuff can be written in a source code file, using any number of ways to represent them (i.e., yet another layer of "encoding"). Remember a source code file is itself already mired in this complexity. For example, you could want to represent undisplayable ASCII characters (i.e. that don't have a corresponding visible symbol) on a 64-bit Linux machine but using a source code file that respects the Apple Macintosh conventions (for newlines, etc.), or want to represent a Unicode character that requires 16 bits, but using a computer that only has 8-bit characters, and do this with ASCII characters representing hexadecimal symbols, etc.
Anyway, I'm not even sure I completely grasp how complicated the problem is, but I do see there is a lot of complexity.
The double-quote begins all the various kinds of string litterals. The parenthesis are re-used as start and stop symbols for strings (like they are reused for multi-line comments). In between the first double-quote and the opening parenthesis, there can be a number. Since there is such a huge variety of different string formats, we just number them (i.e. the number is a kind of "file format", like ".EXE" or ".TXT" or ".PDF", but for string litterals). The number corresponds to a format defined by somebody else (I don't want to reinvent yet another standard). If there is no number, it's the default for GePSyPL, i.e. the bog-standard old-fashioned null-terminated 8-bit character ASCII string like in C. Some examples:
# Boring string (notice double-quote before closing parenthesis) "(Hello World!") # String with a bunch of parenthesis. "(Who cares if(there)are ex(tra parentheses?") # Same, but with necessary escape character "\" for double-quotes "(Careful if\"you have extra \" double-quotes") # Whitespace (tabs and newlines) are fine, they will be preserved # (Limerick refers to replacing " with « and » ). "( GePSyPL strings are ugly, Too many keystrokes for me, but digraph grepping is less frustrating than searching manually. Man E. Tabs ") # If you want just one single character, like 'a' # (notice there is no ending single-quote) "'a # Some weirdo string litteral format "23(Ηελλο ωυρλδ") # The empty string! No parentheses needed! ""
# This is an "end-of-line" comment. #( This is a "multi-line" comment. #( Which can be nested, #) for example to comment out areas of code that already contain multiline comments. #)
Visual Metaphor:
As reader FG suggests, we could re-use the trick used to write Unicode string literals in order to allow Unicode (and other formats) comments.
Should we have "significant ASCII art"? e.g. "#=======" or some other YAML-type separators and "adornments" of source code that would have semantic content?
"Positionish" likes "Genus-Species" ordering, and in a way string litterals and comments (and maybe other language constructs) can be seen as having such "Genus-Species" ordering:
#@responsibilities( - The genus is "comment", but with an annotation, it becomes a more specific kind of comment, a "responsibility description" comment. #) "999(The genus of this is a string literal, but specifically a 999 species of string")
OK, I'm not saying this is a brilliant idea, but I need a short keyword that says: "And now, this type or subprogram has the following properties or attributes or characteristics, whatever you want to call them" (Thomist philosophers call them "common accidents"). I thought the dollar symbol was nice, because money doesn't define who you are. Money is something you have now, but even if you didn't have it, you would still be yourself.
For example, a subprogram could be "inline", but even if that changed and you removed the "inline" keyword, the nature of that subprogram would not change. In C++, the keywords "volatile", "mutable", "const" would be examples of other non-essential properties.
You can say in your mind: "having the following attributes or properties" when you see "$" in GePSyPL.
Same as in just about all programming languages I can think of, but with the addition of " ' " (the apostrophe) in front (because of the shortage of ASCII characters):
'= # Equal '< # Less than '> # Greater than '<= # Less than or equal '>= # Greater than or equal 'not= # Not equal
Yes, I hate it too. The additional " ' " is verbose and ugly and non-standard. Here are some reasons why I'm trying this, for now:
- In ASCII, there is a conflict between comparaison operators and template angle brackets "< >", which would dissappear if we could use «guillemets» for templates parameter lists (or some other delimiter from a richer character set).
- I thought of adding a character to the angle brackets used for templates, instead of squatting on the comparaison operators, but when used for templates, they are delimiters, so they are automatically doubled (one to start, one to end the list of type parameters), and they can be nested, like this:
# C++, not GePSyPL: template <map<int,bool>, vector<double>> # Which means six times the added character: template '<map'<int,bool'>, vector'<double'>'>
- Another reason to prepare to dump ASCII is that we could get proper symbols for "less than or equal", "greater than or equal", "not equal", etc.
- The " ' " thing isn't completely crazy. The "=" sign in mathematics is not a question, it's a statement of fact, like "2+2=4". In programming, it is not a statement of fact, it is a comparaison between two values to see if they are equal or not.
- The " ' " is visually boring and meaningless, which is great since it's just a hack to temporarily simplify lexical analysis. The fact that nothing vivid jumps to your mind when you see the " ' " character is appropriate.
- Another advantage of this kludgy solution is how easy these weird character sequences can be found with a simple search-and-replace, whereas ambiguous and over-used angle brackets are harder to sort out. So changing our mind later on doesn't cause too much grief.
Not much to say about the basic arithmetic operators:
+ addition - subtraction * multiplication / division
For now, because of the extreme shortage of ASCII characters, I follow Pascal and use keywords for less common operators like:
mod modulo or remainder ("%" in C/C++) div integer division
I'm not sure yet about the unary minus. I would like a separate ASCII character which would also be commonly used in normal mathematics, to have two distinct symbols for unary minus and binary minus. It would simplify lexical analysis (we would just declare that a number may not start with a decimal point or a minus, so as soon as the scanner sees a number character, bingo, it's a numeric value), as well as avoid some ambiguities caused by combination assignments ("x = -8" is totally different from "x =- 8"). Some calculators have it, a kind of tiny minus sign as a superscript (-).
Maybe a postfix unary minus? (Argh! Ugly! Non-standard! But don't worry, this is just an experimental language!)
3 (plain ordinary integer) 0.23442 (floating-point number) 8.23442-**1000- (really small negative floating-point number) 8772- (negative integer) -34422 (error) x = -8 (error) x =- 8 (OK, equivalent to "x = x - 8") x = 8 - 4 (eight minus four) x = 8 -4 (eight minus four, i.e. you don't need a space between the "-" and the "4") x = 8- 4 (error) x = 8- - 4 (OK, x is assigned negative eight minus four) x = 8 - - 4 (error) x = 8 - -4 (error)
Visual Metaphor:
In C++, beginners are often confused with "*" meaning either "dereference this pointer" or "declare a pointer", and "&" meaning either "take the address of this object" or "pass this parameter by reference" (or even "rip the large object away from this handle" with a double "&&"). In GePSyPL, all "address-related" things start with the "@" symbol (address, or "at"). When the "at" symbol is alone, it means "take the address of what follows". When followed by the caret "^" (which looks like a little arrow), it means "go to the memory cell pointed to by this", i.e. "dereference the pointer".
module $ trustme # Necessary because we're fiddling with raw pointers. var i 0 var pointerToInt @i # Now lets stick the number 7 in that integer variable, but # using the roundabout way, i.e. by putting the number 7 in # the memory cell pointed to by that pointer, i.e. by # "dereferencing" the pointer to that variable: @^pointerToInt = 7
I'm not sure yet, but if I cannot sort out the whole "rvalue reference" mess, then more operators could be added:
var ii 0 var ii_alias @& ii # Now, "ii" can be accessed with either "ii" or "ii_alias". ii_alias = 3 screen ii # Displays "3" type SomeType # "Move" constructor, i.e. "s" will come out of this constructor # without even the shirt on its back. ctor[% s @&& SomeType]
One of the advantages of preceding all the "address-related" stuff with "@" is that we can then re-use "^" and "&" to begin other families of operators. (In other words, we free up some of those very rare ASCII characters.)
What is the best assignment operator? I tried several, and they all seem to have disadvantages.
=> (equal + greater than)
Pros: beautiful
visual metaphor
to explain meaning; explicit direction (left-to-right) so students know right
away which value is being "crushed" by the other value; left-to-right
direction is consistent with reading direction. Cons: two hard-to-reach
keystrokes for one of the most frequent symbols; totally unusual (i.e. all
programmers have to be "re-educated", which causes much pain); left-to-right
direction makes parsing harder and is totally unusual; left-to-right direction
also goes against another important ordering rule
(genus before species),
since when assignment is right-to-left, the "sum" or "overview" is on the left,
and the "explanation", the "details" are on the right, like:
total = price * quantity + taxes
:= (colon + equal)
Pros: Second most frequent assignment symbol (after the crushingly-frequent
plain "=". Cons: all the disadvantages of two keystrokes, with no clarity on
direction, and no obvious visual metaphor.
<- (less than + minus)
Pros: Clear direction of assignment. Cons: all the disadvantages of two keystrokes,
with no obvious visual metaphor. If reversed to "->", adds all disadvantages
of left-to-right assignment.
: (colon)
Pros: single keystroke; does make a bit of sense (i.e. the "left-hand-side" is
"explained" or "explicited" by the right-hand-side, like normal English
punctuation). Cons: No clear directionality, no good visual metaphor,
totally unusual.
another symbol (&, %, #, etc.)
Pros: Single-keystroke. Cons: Almost all of them, especially being totally
unusual.
one or several keywords, like the COBOL "move X to Y"
Pros: with the right words, can be made as explicit and clear as anything
ever could be. Cons: hysterically verbose for such a commonly-used symbol.
Currently, I bow to the almost-universal plain equals sign "=" (while simultaneously begging for a RomaCode assignment symbol), and accept the penalty of not indicating directionality, but not changing the almost universal right-to-left assignment order either (which compensates a bit). There is a bit of a visual metaphor that can be used, and after assignment the result is two memory regions with the same bit patterns, so it isn't so bad. If we maintain the fussy and verbose "logical comparaison operator", it does have the advantage of automatically freeing-up "=" to mean assignment, and makes errors easy to detect for the compiler.
Visual Metaphor:

Like many other languages, assignment can be combined with other operators, but we start all these "combined-assignment" operators with "=", so scanning is simplified.
var left 6, right 87 left =+ right # Add "left" and "right", then put result in "left". left =* right # Multiply "left" and "right", then put result in "left". # Etc. (-, /, mod, div, all the bitwise operations)
Both procedures and functions can have parameters. Even if there are no actual parameters, the square brackets "[]" must be there after the subprogram name.
gepsypl # Notice square brackets, not parentheses, for the parameter list. proc doSomething[someInput int % someOutput bool] # The subprogram code goes here.
Visual Metaphor:
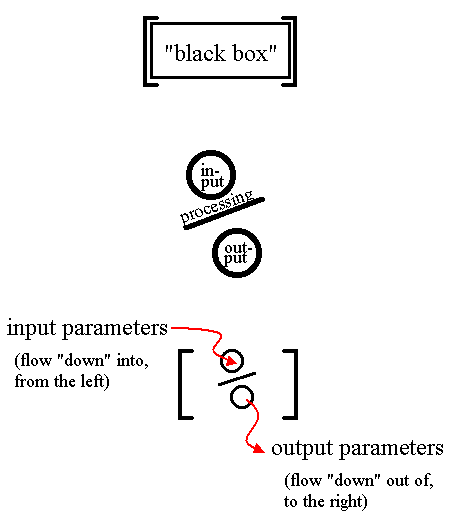
Just about everybody uses parenthesis to indicate subprograms, so choosing another symbol is a big decision. Many programmers will complain about this big change! But I think it's justified. Not only is the visual metaphor more striking (and the concept of a "black box" is one of the most important concepts of programming), but it also greatly helps parsing (there is no ambiguity: if the parser sees an opening square bracket, it's a subprogram).
Because the formatting of the source code is significant, we need to be able to say "ignore this newline, I need to put all this stuff on the same line even though my sheet of paper (or computer monitor) is not wide enough".
Just say "bit" in your head everytime you see "`" (ASCII symbol number 96, a.k.a. the "back-tick") in front of an operator. Also, binary literals also start with "`":
`001 `and `111 # Bit-and, result is `001 `010 `or `100 # Bit-or, result is `110 `010 `xor `111 # "eXclusive-or", result is `101 `100 `>> 2 # Right-shift, result is `001 `010 `<< 1 # Left-shift, result is `100 `not `010 # Bit complement, result is `101
Of course, RomaCode would give us a far superior symbol.
Not sure yet. Maybe a specific language feature for "serialization", also called "externalization", as in "take something inside the computer and externalize it to a plain text file that can be read by normal humans, and which can also be read into the computer later on". C++ already has such a feature, a bit, since you can say things like:
# C++, not GePSyPL: vector<int> toto = { 8, 3, 99, 0, 4 };
I would like something simple like YAML (I intensely dislike the verbosity of XML), in combination with these curly braces, to allow the source code to be a database for serialized objects. What objects? Hopefully, all the useful ones! Not only serialized objects that are used in a computer program, but also the UML diagrams that describe that program, the GUI forms used by that program, etc. In other words, GePSyPL would become the public highway of software development tools.
For reasons only partly clear to me, good programming seems to require good diagramming. Whether the UML (Unified Modeling Language) or others (I would like "SoMoNo", the SOftware MOdeling NOtation), a good "software modeling language" helps us build good software.
Shouldn't programming languages try to be more "compatible" with UML, even if only in their "syntactic sugar"? Wouldn't it make the life of programmers easier, since their brain would be able to "flow more easily" between programming and diagramming?
What would GePSyPL look like, if we tried to make it as compatible as possible with the UML? Or am I just going overboard with "ASCII art"? One advantage of an experimental programming language is that we can make experiments! Let's take four of the most common relationships in UML:
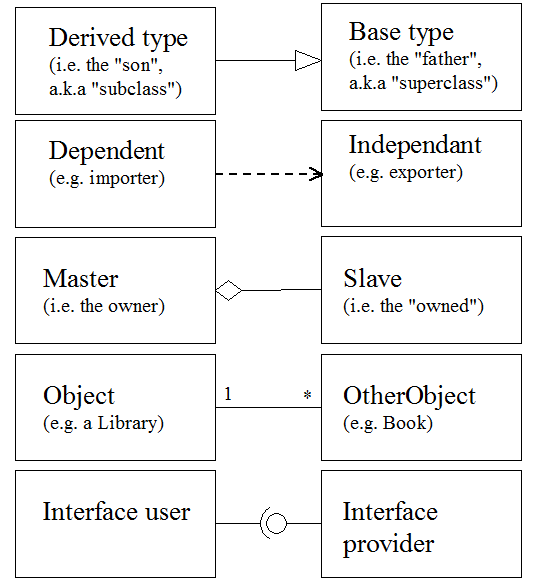
Let's agree that the "|" symbol means "relationship" (it does sort of look like a line connecting two things), we could then have:
# Relationship of inheritance: type Son |> Father # List Son's variables and member subprograms here... # Relationship of dependency («imports» stereotype): import Atom |-> Proton Neutron Electron # Relationship of ownership: type Person |<> name str, age int, isHungry bool # (Unfortunately, the lozenge or diamond should be filled, not white, # to respect the UML convention for "strong" ownership.) # Relationship of multiplicity: # (Inspired by Dr. Timothy C. Lethbridge's Umple) type Library |1--* books arr<Book> # Relationship of interface: type Citizen |(o- Taxable # A UML lollipop emoticon? Lord have mercy on us! ;-)
Could a general-purpose systems programming language also be a textual representation of a software modeling notation? Conversely, could a software modeling notation be "enhanced" up to the point where it could be used to generate the complete source code of a program? I don't think so. I think their aims are too different:
- A good diagram must hide irrelevant and distracting details, and help programmers concentrate on the few important things that help understand all the rest. On the contrary, a programming language has to tell a stupid machine what to do, with all the details, without missing anything.
- A good diagram is positions, sizes, colors, icons, etc. There are no such things in a programming language. A type is not "more to the left" or "of a more pale green or blue" than another type. "Integer" does not occupy a greater area of the computer monitor than "Boolean" or "Floating-Point".
Yes, a program will describe types and give them names, so a diagramming software can read the computer program source code and draw boxes and give them names. In the same way, a programming software can read a diagram and generate some source code. But in my experience, the result is either a diagram that is a big blob of visual clutter, or source code that is a dead skeleton that turns to dust if you try to pick it up.
Assuming one cannot replace the other, can the programming language and the modeling notation at least collaborate? I think it's possible.
On the one hand, GePSyPL is very easy to parse, so diagramming software can easily understand what is inside GePSyPL source code. On the other hand, diagramming software can store some of its information in a format understood by GePSyPL, preferably under the control of the same software configuration management product.
How would both programming and diagramming tools collaborate? I'm thinking out loud here, but perhaps the diagramming tool could tell the programming tool something like: "Hi buddy, here is a list of things in your source code that I'm currently displaying on my diagrams. Would you mind giving me a heads-up before changing them, so I could either update my diagrams automatically with your minor changes, or warn my user that your major changes have now broken this and that in the diagram?"
See also: Round trip engineering for dummies: a proposal
Heavily inspired by Java annotations. Originally, this feature is caused by quirks of my personal programming style: (i) I love code samples showing other programmers how to use whatever thingy I'm programming, and letting them just "Copy-Paste" compilable code into their programs; (ii) I love to document my design decisions as I'm inventing something; and (iii) I hate it when (i) and (ii) are either mixed up with the code (Lord! The clutter!), or in another file (Darn! I need those code samples to imagine "use cases" of how other people will use my software products, and I need those design decisions to remember why I did something this way instead of that way, or that other way).
module SomeModule type SomeType # Code here... proc SomeProcedure # Code here... # ... Far, far below at the bottom of the file: #@design_decision SomeModule.SomeType #( - Why call it "SomeType" and not "MyType"? Because bla-bla-bla. - Should "SomeType" be an abstract data type or a concrete data type? For now, I'm making it bla-bla because bla-bla, but that could change if bla-bla. #) #@design_decision SomeModule.SomeType.SomeProcedure #( - I can't make it latebind (i.e. "virtual"), because this procedure gets called thousands of times inside a critical loop. #) #@code_sample SomeModule.SomeType.SomeProcedure #( # First, assemble the necessary input parameters: var ParameterPackage pp["password: 23skidoo" true ATOMIC_OPERATION] # Call the procedure. No need to create an instance of "SomeType", # because it doesn't use any of its data members: SomeModule.SomeType.SomeProcedure[pp] #)
Just a standard assertion. In a "test" section, there is no need to supply a message in case of failure, since the test case name is used for that.
Same thing as for all scoped languages like C++ (which uses curly braces "{}"), or Pascal (which uses "BEGIN" and "END"), etc. In GePSyPL, we use indentation:
// C++, not GePSyPL: void someFunction() { // Lots of code here... // Then we enter a new block: { BigObjectWithDestructor bo; } // The destructor of "bo" is called here, implicitely. // More code here... } # Equivalent code in GePSyPL: proc someFunction[] # Lots of code here... # Then we enter a new block: block BigObjectWithDestructor bo; # The destructor of "bo" is called here, implicitely. # More code here...
If you compare both code samples here above, there are nearly identical. This is because no programmer is crazy enough to ignore whitespace, even if his programming language does. Also, you rarely see explicit "block" statements in real code (C++ or otherwise), since statements like "if" and "while", etc., are usually also implicitely "block"s. Sometimes you need a "naked" block for resource management (such as entering a critical section in a multithreaded program), and it's also nice to teach beginners about blocks, when you have a keyword called like that! Finally, if you cannot for some reason use indentation to mark the beginning and end of a block, you can use the secondary keywords "block.begin" and "block.end".
Just a primary keyword on which to "hook" secondary keywords equivalent to the C++ "sizeof()", "decltype()", alignas(), etc. This allows us to keep a bunch of names out of the global namespace, and to make things a bit easier to explain to students.
if compiler.sizeof[int] '< 4 screen "(Wow, this CPU has really small registers!") # Print the source code file name and the line number for the # following statement: screen compiler.youAreHere[]
Roughly the same thing as the "var" keyword, but for compile-time, not run-time. In other words, a "const" is roughly a degenerate "var". Like a variable, it has a name, a type and a value, but it might not have any run-time memory allocated to contain it (since it's not supposed to change, ever).
# You can define ordinary constants: const MAX_NUMBER_STUDENTS_IN_CLASSROOM 22 TOTAL_CLASSROOMS 4 MAX_STUDENTS = MAX_NUMBER_STUDENTS_IN_CLASSROOM * TOTAL_CLASSROOMS NAME_OF_SCHOOL "(SmallTown High School")
Same as C++, but explicit keywords, among others because it's easier to explain to students, and they are usually shorter than the actual type name.
Modules can have constructors and destructors too. Module constructors are called in the order of their appearance in the "import.level" section of the main module (the "gepsypl" section), and their destructors are of course called in the reverse order. (Should packages also have ctors and dtors?)
When there are many choices, and you want one to be the default. For example, the default subprogram (procedure or function) of a module.
Just for keystroke reduction. Whatever follows "dup" is duplicated for everything that is "included" in the "dup block". For example:
dup outputstream.write[] "(Hello, ") title "( ") name "(, how are you?")
is equivalent to:
outputstream.write["(Hello, ")] outputstream.write[title] outputstream.write["( ")] outputstream.write[name] outputstream.write["(, how are you?")]
Almost identical with C++ "enum class", which is itself a kind of degenerate "class" with only one member variable (normally plain integer) whose possible values are usually less than a dozen, and where each of those few values can be referred to with a name.
Like the C++ "public", but for modules and packages. See also interface.
I admit I despise the Java "classpath". I hate it with a passion! I remember epic battles trying to figure out what exactly Java was compiling. Why couldn't I just clearly say where each file is, right there in the source code, so there would be no ambiguity whatsoever, especially about such an important thing?
I also have very negative memories about "LNK 2001", which many years ago was the error given by the Microsoft C++ compiler when it would realize, in the middle of baking your cake, that it didn't have any eggs (or milk, or butter, etc.). Why not check to see if you have all the bloody ingredients, before you start baking the cake? Is that so complicated to understand?
Normally, the first line of a GePSyPL program is the "filemap" statement. You won't see them often here, because I give little toy examples, so I don't need more than what the programming language offers (i.e. the actual language and the standard library), so there is no need for a "filemap". Also, there can be several "filemap" statements, expecially for large programs, where the main "filemap" statement would just point to a "master package" which would itself have a "filemap" (perhaps leading to others, etc.).
See "package" for an example of a filemap statement.
# Let's count to 10: gepsypl const anArrayOfIntegers {1 2 3 4 5 6 7 8 9 10} # It's always "foreach", then an element, then the container: foreach i anArrayOfIntegers screen i "( ")
I could be wrong, but I think C++11 killed the venerable C-style for-loop. First, you can do any loop with "while". Second, with iterators and containers, "foreach" becomes (as far as I can see) safer, easier to type and clearer to understand.
Secondary keyword used to solve the "chicken or egg" problem caused by the "define before you use" rule, when two things need to be defined at the same time because they are connected to each other. Same as Pascal (but secondary keyword because it's not important).
type.forward LinkedListNode # OK, now you can make a pointer to a "LinkedListNode", # even though "LinkedListNode" has not been defined yet. var pNode @LinkedListNode proc.forward willBeDefinedLater[i int, f float] # Lots of code here... # Now call an undefined subprogram: willBeDefinedLater[someInt someFloat] proc willBeDefinedLater[i int, f float] # Eventually, you must define that function, # so add code here.
Not sure yet, but I'm trying something: a compiler-enforced distinction between a "procedure" (Pascal terminology) and a true "function", i.e. something that returns one value and has no side-effects. In other words, a "function" is a kind of degenerate procedure.
If we were to describe a GePSyPL function using C++ terminology, we might say: a GePSyPL function is "constexpr", cannot have a "void" return value, cannot avoid returning a value, receives all input parameters as "const", does not return "&" output parameters, does not allow "move() constructors" on input values (i.e. everything is fully copied), etc.
Will this "cramp the coding style" too much? Will this give any advantages in clarity or ease-of-use, etc.? I don't know yet. Maybe all functions will automatically be "re-entrant", i.e. suitable for multi-threading? Maybe it will be easier to explain "functional programming" to students? Maybe more code will be executable during compile-time, hence reducing what needs to be executed at run-time?
(I'm not too sure about the syntax yet, but I think I like the idea of named return values in the function signature. Although you could say the name of the function should make that pretty clear.)
stric Registerable # Code to only allow objects that fit inside a CPU register. type TimeUnit $ Registerable # Definition of this new type goes here. # By putting the name of the returned type to the right of "[]", you # declare what will be returned by that function: func getTime[] TimeUnit var t TimeUnit # Code to communicate with the Operating System to get the # current time, convert it into a usable format, and # stick it in "t". # Then, you just make the last line of the function # be the value you want to return: t # Et voilà. Nothing else. No "return" statement.
# The usual first program: gepsypl screen "(Hello world!")
# You can tell the compiler what name to give to the ".exe" file. gepsypl Name_Of_Executable # ... program source code
gepsypl Getting an input string from the user screen "(Please type your name, then press ENTER.") var name str keyboard name screen "(Hello, ") name
Why require the "gepsypl" keyword to start every program?
For students learning a new language, it makes more sense pedagogically: you're teaching this weird new language with a weird name, so starting a program with "int main(int argc, char *argv[])" seems less intuitive than "gepsypl".
For professional programmers attempting to understand a very large set of source code files written by other programmers (i.e. "grokking a project"), it is very pleasant to be able to just search for a keyword to find the "head" of the project. In other words, you are given a huge "haystack of source code files", and you want to find "the needle", the starting point that you can pick up and use to understand the whole system. (Which is why courteous GePSyPL programmers put "gepsypl" in all lowercase just once in a project folder, so any other programmer can just download that folder, and quickly find where to start learning.)
Why is the "gepsypl" like the "project head"? Two reasons. First, the language forces the program to start with "gepsypl" and doesn't allow you to "import" any modules or packages into your project without first specifying where the compiler is to find them (i.e. the filemap statement). So right from the start you can find out what are all the materials that will be used for compilation, i.e. all the source code files (and static and dynamic libraries, etc.), as well as their location. Second, the language forces you to import all the modules and packages that your program will use into the "gepsypl" module. Even if the "gepsypl" module doesn't use them directly, it has to import them directly. (You still have to import what you need in each other separate module and package, but this must be duplicated in the "master import" statement in the "gepsypl" module.) And since the "import" statement in the "gepsypl" module must be levelized, that means you get a hierarchy of modules and packages, not just a big heap.
A minor reason for professional programmers mucking around with several languages on the same project: your brain eventually gets confused, and seeing "gepsypl" right from the start knocks you back on track. (OK, I've gotten confused. Probably not you!)
I might allow all the other names to compile (nunskin, teamtractor, syntaxbride, positionish), at least in Easter Egg mode, if only to make people laugh, and to help them remember the design intentions for this programming language.
Included in the language mostly so computer science teachers can explain how lucky we are to have structured programming. Module where it appears must be "enabled" with trustme keyword.
gepsypl $ trustme # Lots of code here. # Ye olde "while loop" without a "while". var i 1 goto.target WHILE_START screen i " " ++i if i '> 10 goto WHILE_END goto WHILE_START goto.target WHILE_END
To make groups of things in the source code, moslty to facilitate documentation, but also to reduce keystrokes. Doesn't change the behavior of the executable. Totally useless for tiny code samples like all those on this page, but very useful on million-line projects!
type SomeBigType # This "sticky comment" will be automatically # associated with this group. The group also # has a name which can be used by other tools, like # a class browser or an "Intellisense" code palette, etc. grp DatebaseUpdaters # Of course, each subprogram can also have its own sticky comments. proc putThisIn[] # Lots of code here. proc takeThatOut[] # Lots of code here. # You can also use groups to give several things the same properties # (giving a group a name is optional): grp $ inline proc quickieSubprogram[] proc anotherQuickie[] proc yetAnotherQuickie[]
Might also make it easier to connect the programming language with an RAD IDE like Delphi or Visual Basic. For example, a whole bunch of member variables could be declared "grp $ IDE" or something, so the RAD would know to display all these variables in the "Properties" dialog box.
Roughly along the same lines, Microsoft's MFC "MESSAGE_MAP" (and other similar GUI event handler features) might be easier to connect with the programming language that way.
gepsypl screen "(Do you want to learn programming? ('yes' or 'no', then ENTER.)" var answer str keyboard answer if answer '= "(yes") screen "(OK, let's start!") elif answer '= "(no") screen "(Snif... But I will always love you! ;-)") else screen "(Sorry, I don't understand your answer.")
Roughly equivalent in most modern programming languages (which means C++ still isn't modern, since it doesn't yet have modules! ;-)
I have many questions about how "import" should work:
- I know I don't want a silly separation between ".H" and ".CPP" files (too much work to keep them in synch, too many duplicated keystrokes, too many opportunities of failures because of missing files, etc.). But the separate headers have advantages (not showing your source code and just sending the ".H" files, having "#includes" that are different for the ".H" and ".CPP" files, brutal simplicity of the mechanism). How can we compensate for those disadvantages?
- should I force the programmer to repeat the "import" clause at the "top of the module" (i.e. the "private part"), and later on in the "public part" of that same module (i.e. the "export" section)? Or should I just say: list everything you need at the top of the "private part", and I'll figure out the minimum actual imports required for the public section"?
- I dearly want the compiler to check that everything is ready for compilation before compilation begins (hence the "filemap" and "import.level" statements). But this means the "import" statement at the top of a module is duplicated at the beginning of the "gepsypl" statement?
- because the "export" keyword will be potentially used so many times inside one module, should the actual module "public part" have a special name, like "export.module" or "module.interface" or "module.public", so the compiler could just "grep" for it and quickly find what it needs when it hits an "import" statement (i.e. it would not need to parse all the indentation to figure out if this "export" statement was for a type or the actual complete module)?
- etc.
In the "gepsypl" module, there is a special "import" statement, the "master import" statement. For example:
import.level 1 Proton Neutron Electron import.level 2 Atom |-> Proton Neutron Electron import.level 3 Molecule |-> Atom import.level 4 Protein |-> Molecule FoldingAlgorithms AminoAcids
Looks like a subprogram, but it's not. There is no actual "function call", no "subprogram activation record" placed on the stack, etc. Contrary to C++, "inline" either causes a compilation error (if I'm not smart enough to inline what you're passing me), or it works.
proc quickie[] $ inline # Simple code here that will just be "in-lined", i.e. added as is # to the program, every time this "pseudo-subprogram" appears.
For now, I'm throwing all predefined types into the same section. Most of them are just plain C/C++ predefined types, sometimes with a few twists.
# Standard predefined types (this code would not compile, it's just # to show the type names). int # Integer bool # Boolean, true or false char # Character float # Floating-point. Careful: corresponds to "double" in C++ # Types that are considered predefined in GePSyPL, but # that C++ could consider as "in the Standard Library". str # String of char arr # Array (i.e. the C++ mis-named "vector") list # List map # Map # Many of the "more complicated" types have # "variations", i.e. different implementations. arr.raw # The old-fashioned C-style array, i.e. "raw" contiguous bytes. Requires "trustme". list.forward # Singly-linked list (i.e. you can only go "forward") map.hashed # The C++ "unordered_map"
Not sure yet. In theory, the "export" keyword is sufficient. Both types and modules (and packages) can "export" things, i.e. make things part of their public interface. But by limiting "export" to modules and packages, that means you can parse a source code file more quickly to skip over all the private stuff of a module. You don't need to keep track of whether you are currently inside a type or just outside the module. You just look for "export", and bingo, you're there. Unfortunately, "interface" is a bit long to type, but it is a nice keyword, very useful for students.
Just an attempt to have a more meaningful keyword than the C++ "virtual" to describe subprogram names that are "bound" to the actual machine code that will be executed at a later time, i.e. during run-time, not during compile-time.
I have personal misgivings about "template metaprogramming", but what if those features were also present in GePSyPL? What would it look like? In C++, selection is done with "SFINAE" ("Substitution Failure Is Not An Error"), and repetition is done with template specialization ending a recursion on a variadic template argument list (if my very small brain is correct). In GePSyPL, since we have the luxury of adding keywords, and since keywords can have "members", i.e. secondary keywords, we can just say:
gepsypl # Lots of code here... # Suppose we need to choose a type during compile-time: meta.var Toto type # And suppose we have some kind of compile-time condition: meta.if fooBar '= true Toto = int meta.else Toto = str # Et voilà! Now "Toto" can be used to declare a variable of the right type. # (Note we are no longer in a "meta" region of code here.) var t Toto # Now suppose we need to iterate during compile-time: meta.var i 1 meta.while i '< 11 # Do whatever metaprogramming needs to be done 10 times here... ++i # Here, give thanks to the Lord for having avoided many long # and useless hours of study to understand how C++ does this.
This module is actually hard-coded in the language, so this will not compile if you try it. But if it wasn't, this is how it would be done:
module Wisdom export proc default[question str % answer str] if question '= "(What is the meaning of life?") "(Catechismum Catholicae Ecclesiae §1/2865") => answer else "(Da veniam mihi, quaestio tuae non intellego.") => answer
(It's very useful as a reminder that: "(...) just about any task can be rendered simple by the use of good libraries." [Stroustrup 2014], p. 87.)
A longer example, showing "private/public" (or "implementation/interface") divisions inside a module.
module ModuleWithPrivateParts # This subprogram is invisible outside this module. proc invisible[] # Some code here ... type SomePrivateType # This type has one member variable, an integer, which will # be initialized to zero upon creation. var i 0 proc SomePrivateSubprogram[] # Of course, a type has access to its own members! ++i interface proc doSomeThing[] invisible[] export proc visible[] # People who import "ModuleWithPrivateParts" cannot see or have access # to the private parts, but we do, since we're the programmer coding # this module. var s SomePrivateType s.doSomeThing[] # Commented out, because it would be an error. Outside "SomePrivateType", # nobody has access to this subprogram: # s.SomePrivateSubprogram[]
(I thought of calling them "gepsypl.module" instead of plain "module", but that would have made it harder to "grep" for the main module, i.e. the start of the program.)
Should modules have latebind subprograms ("virtual functions")? Of course, it could be done (in software, just about anything can be done), but should it? A related question is "What is the difference between a module and a type"?
|
|
Type |
Module |
|
General intent |
Logical design |
Logical design, and a
|
|
Number of instances |
As many as you want |
Just one (because of the
|
|
Can be instantiated, used as
|
Yes |
No |
|
Variables, constants,
|
Yes |
Partially. Anything that involves
|
In the case of a "degenerate" module which contains essentially only one type, you can "fake" a "type/module" by making that one type the default type for that module:
module TinyModule export type default # Put variables and subprograms here # Then, in another module you can have this: module SomeOtherModule import TinyModule var tm TinyModule
What is a package? And what is the difference with a module? Should a good programming language even have "packages"? (and even if so, should the keyword be "package" or some other word?) Let's compare packages and modules:
|
|
Package |
Module |
|
General intent |
Physical design |
Logical design |
|
Variables, constants,
|
No
|
Yes |
|
Other packages and
|
Yes |
No |
|
"filemap" statement |
Yes |
No |
|
Can be individually compiled
|
Yes |
No |
I don't know how to do it, but I'd also like to integrate all the advanced levelization techniques of John Lakos into the programming language.
Let's imagine a typical package:
package.dll Networking # Declaring string constants is about the only "programming" you # can do in a package, mostly to simplify "filemap" maintenance. const NETWORK_DRIVE "(F:/") filemap Packet "(/BigCorporateHardDrive/CorporateCodeBase/utils/Packet.ge7") SocketBase "(/AnotherBigCorporateHardDrive/CorporateCodeBase/networking/Socket.ge7)" RoutingProtocol NETWORK_DRIVE + "(Vendors/Routing/RoutingProtocol.ge3)" import.level 1 # Imports can be modules or packages, it doesn't matter. Packet import.level 2 # Note use of UML dependency icon. Socket |-> Packet import.level 3 # A module or package that is "higher" in the acyclic dependency graph # can depend on several different levels, as long as they are "lower". RoutingProtocol |-> Packet Socket export namespace.merge Packet SocketBase.Connections.Socket RoutingProtocol.Adaptative
Another feature I'm considering is forcing the programmer to indicate packages that contain other packages, along what Mr. Lakos says:
package MyLakosianSubsystem # This package only contains modules. package package MyLakosianGroup # Because the keyword "package" is doubled, # that means this package contains other packages # (which themselves do not contain other packages). package package package MyLakosianBigKahuna # Because the keyword "package" is **tripled**, # that means this package contains at least one package # which itself contains packages. (And so on. Repeating "package" # like this makes it immediately apparent that you're looking at # some "monster package").
I could just say "package.1" and "package.2", etc., to explain "how many Russian dolls are contained in this Russian doll", but by repeating the word "package" I make it bloody obvious and intentionally verbose.
If you're unsure whether to use a procedure or a function, use a procedure. Functions in GePSyPL are a bit weird. See also Subprogram parameter list and function.
gepsypl # Notice first two parameters will be "read-only", third one will be writeable. proc aSubProgram[i int, b bool % s str] # No problem, reading the contents of something read-only is permitted. var anotherInteger i # The following line is commented out, otherwise the compiler would # stop and complain about an error: # b = false # But of course, for the sake of output, a function can return some # information! s = "(This comes from inside 'aSubProgram' !") var someOutput str aSubProgram[4, true % someOutput] screen someOutput
What should we call this thing? To my great chagrin, the litterature is filled with different names, like "subroutine", "subprogram", "function", "procedure", "method", "callable unit", etc. To make things worse, they all have disadvantages.
"Function", in many programming languages, is not mathematically correct (functions, strictly speaking, don't have side effects and always return a value). But the top three most popular programming languages these days, i.e. C, Java and C++, just call all subprograms as "functions". (This has many advantages, like simplicity in the vocabulary!)
Insisting on two different keywords for "out-of-a-type" and "inside-a-type", i.e. "function" vs. "method" seems incorrect to me. A subprogram is a subprogram. Yes, it can be a member of a module, or a member of a type, but deep down inside it's still a subprogram.
Insisting on two different keywords "function" and "procedure" just for some syntactic sugar for returning a value seems incorrect too. "Procedures" can return plenty of values (with "call-by-reference" parameters), and most languages have "functions" that can return nothing. But what if the compiler enforces a more strict definition of "function"?
"Sub" is lousy for many reasons: (i) I hate talking about "subs" (what? submarines?); (ii) it differs from common usage (i.e. just calling them "functions"). There are some advantages to "sub": (i) some languages use it (like Basic); (ii) "sub" is a short keyword; (iii) "sub-program" is very descriptive, since that is what it is! A subprogram has input, processing and output, like a big program! (iv) the fact it is not the most frequently-used word (i.e. the word "function") might actually be an advantage, since GePSyPL is notationally a bit different from what programmers are used to (so making them look different might actually help programmers).
Should procedures be allowed to return simple ("registerable") values? This would be a convenience (like "if Scanner.isKeyword[% token]"), but also mark functions as distinct for reasons other than syntactic sugar.
Memory that is "statically-allocated" in the "program text" by the compiler, once and for all, before the program is executed (as opposed to "dynamically-allocated memory", which is "dynamically" produced either on the stack or on the heap). Normally, when the operating system loads the file containing the executable program into main memory, it also leaves extra room for all the "static" variables. See var for an example.
I dislike the word "static" because it's vague. "program_file"? "comple_time_allocated"? (Yuk!) Also, I made it a secondary keyword because static variables are not used that often, and they can cause many problems, especially when used inside types (they are not thread-safe, and are often just thinly-disguised global variables, etc.). But as far as I can see static variables are necessary, among other because some very simple embedded systems only have static variables, and also perhaps for efficiency reasons.
(Note to C++ programmers: in C++, "static" has many other meanings; here we are only dealing with one.)
C++ has been battling for years with a mistake in the "template" feature:
template<typename T> void blowNose(T hankerchief) { // Code to blow your nose and wipe it with some "T" // that is hopefully safe, absorbent and disposable. } PoisonIvyLeaf p; blowNose(p); // Rats, this compiles. SteelWool s; blowNose(s); // DUH, so does this. 1000dollarBill b; blowNose(b); // Houston, we have a problem...
We would like to say something about the "T" that will be used to instantiate this "template function" (in C++ terminology). We would like to restrict the types that can be passed, without being too restrictive.
In "pure" object-oriented languages, the answer is simple: there are no templates, and you just make a "Hankerchief" base type from which you can make all other suitable types derive, like the "OldNewsPaper" type, the "NonPoisonousLeaf" type, the "HeManShirtSleeve" type, etc.
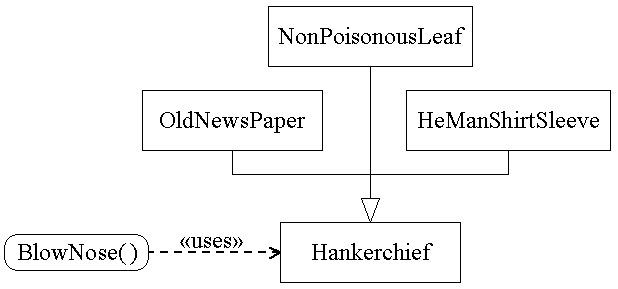
The "Hankerchief thing" will have many names, depending on the programming language. In Swift, it could be implemented as a "protocol". In C++, it could either be an "abstract base class with only pure virtual functions", or in a futur version of C++, it could be a "concept" usable by templates. But whatever the name, it would still be a kind of "contract" between the "blowNose" subprogram and all the potential things that claim to be safe, absorbent and disposable.
In [Stroustrup 2014], p. 707-709, a "concept" is a "semiformal" description of "semantic requirements", "a very general idea that does not inherently have anything to do with templates". It is more than an "ad hoc collection of constraints on a type", even though such "a partial specification" of an interface "can be useful and much better than no specification".
I don't know if Mr. Stroustrup would consider the above example of "hankerchief" (i.e something dermatologically safe, absorbent and disposable) to be a "concept". But as far as I can see, a C++ "concept" is like a well-built house, and an "ad hoc collection of constraints on a type" is like a parts of a house's foundations, with parts of walls, a piece or two of the roof, etc. If you want a house, you need house parts. (Yes, house parts can be incomplete or assembled incorrectly, but that just means our nun has to give good housebuilding lessons.)
So what is a "stric"? Saying it's a "restriction on a type" is a good start, but not enough: just about everything in a programming language is a restriction on a type. If you declare an "int" or a "bool", you're restricting the type, just like if you are God and you create a dog, you are restricting that dog and preventing it from being a cat (or a rowboat, or a box of cigars).
A "stric" is a formalization of "duck typing". The old proverb says: "If it looks like a duck and walks like a duck and quacks like a duck, it's a duck". What that old proverb is trying to say is that a thorough and exhaustive induction leads to the nature of a thing. If you grasp the nature of a thing, its "essence", you express that with a type. But if you do not fully grasp the nature of a thing (or if you don't want to fully determine its nature, in order to give more flexibility to the system), you use a "stric". You're basically saying you don't really care if it is, or isn't, a duck, as long as it quacks.
Let's try to imagine what some "strics" could look like in GePSyPL (I'm obviously unsure about the actual syntax, which I'm making up as I go along). A common "concept" or "stric" in programming languages is the P.O.D.S., the Plain-Old Data Structure:
stric PODS var.cardinality 1..* # It has one or more member variables grp $ latebind # Sorry, here you have to look up "grp", "$" and "latebind". proc.cardinality 0 # No "virtual functions", i.e. late-bound subprograms. private.cardinality 0 # Everything is in the "export" section, nothing hidden.
You could use this "stric" to define a "Point" type. Any attempt to have private members or latebind subprograms (i.e. C++ "virtual functions"), etc., would cause a compiler error:
type Point $ PODS interface |<> x int, y int
In C++, you could use "stric" to define "ForwardIterator", "RandomAccessIterator", and other such iterator types used by the STL. It would not in any way improve the speed or compactness of generated code, but would detect errors before template instantiation, and with better error messages on top of that.
I'm not sure, but in Java you have "interfaces", i.e. classes that have only what C++ calls "pure virtual functions". I think I'd implement them with an "ADT stric", a "stric" that allows only "unimplemented latebind subprograms" (i.e. pure virtual functions). I toyed with the idea of having keywords like "type.genus" and "type.interface", etc., but these and other distinctions can be enforced with "stric".
I don't yet know how exactly, but maybe "stric" could also be used to help document software "design patterns", if only as "enhanced comments":
module Patterns export stric HelplessVictim proc helpMe[] stric GoodSamaritan proc beGood[ % h HelplessVictim] h.helpMe[]
Notice the "stric" here above don't say much about what exactly the "GoodSamaritan" will provide as help. The "HelplessVictim" subprogram called "helpMe[]" has an empty list of parameters, but in a "stric", what is not explicitely forbidden is permitted. So no parameters just means an implementation can provide any parameters (including none at all). But the subprogram must be called "helpMe" exactly.
These "stric"s could be used thus:
gepsypl import Patterns type ComputerIlliterate $ Patterns.HelplessVictim interface proc helpMe[advice str] type Geek $ Patterns.GoodSamaritan proc beGood[ % h ComputerIlliterate] h.helpMe["Have you tried rebooting?"]
I'm not sure yet about distinguishing between procedures and functions. To make things worse, I'm not even sure I want the "return" keyword either. What is the problem? Let's consider a few code samples:
// C++, not GePSyPL. This code is fine and dandy (because C! # In old-fashioned C, types are much simpler, and often fit inside a CPU # register, so it's hard to return something large and dangerous from a function.) int someFunction() { return 2 + 2; } // C++, maybe. I'm still confused with "move()" and "rvalue references", etc. I assume "BigType" has a "move copy constructor": BigType getBiggerObject(BigType&& big) { return big + BigType {"(Some constructor arguments here"), 2, false }; } // This is another example of what I'm trying to avoid: // ([Stroustrup 2014], p. 912.) (*(m.insert(make_pair(k, V{})).first)).second
It seems to me that if we "outlaw" normal "function-style" return values, and insist on explicit "output" parameters, many problems are eliminated, with no loss in power for the programming language. I'm not even sure the code would be more verbose, since normally something long to type can be hidden inside a subprogram, and just called succinctly.
I repeat I'm no expert, but maybe there is some deeper problem here. The C++ programming language is a heir to the C programming language. In C, there is nothing wrong with returning values, since most types are bloody simple affairs, like "int" or "double" or "void*". There is no harm in cooking up complicated expressions like:
int toto = i * ii / iii;
No memory on the heap is being allocated or deallocated. No complicated unnamed temporaries are being sloshed around the compiler. But in C++, user-defined types are far more important; actually, it could be argued C++ was invented to allow and encourage user-defined types. One of the design decisions of C++ was to give user-defined types the same treatement (or better!) than what the predefined types receive in C. So this must be allowed:
// With a superbly-crafted "BigType", this can be made legal, and efficient, // in C++: BigType toto = big * bigger / biggest;
In my opinion, a chunk of C++ complexity is caused by this requirement. This requirement is even more bizarre when you consider that such mathematical-looking expressions make sense mostly for mathematical types, which are not infinitely numerous. C++ books often show examples of user-defined Complex and Matrix types, and that's about it. If Complex and Matrix were just supplied by the language itself, would there be such a clamor to provide features allowing the addition of AircraftCarriers and the multiplication of IncomeTaxReturns and the division of PollutedWaterCourses?
# GePSyPL equivalent (no "rvalue references", no doubts # about who owns the object returned by the subprogram): var toto BigType rotateAndScale[big bigger biggest % toto]
I tend to prefer subprogram calls to convoluted expressions. A subprogram can be documented, not only with a clear and explicit name for the subprogram, but also each step inside the subprogram can be explained. So when you see that subprogram called, you can "CTRL-click" on the subprogram name (or whatever other shortcut offered by your IDE) and jump to the complete explanation of what is going on inside that subprogram.
Some might say: "But, but, that is so ugly, so primitive, so ... agricultural!"
Yes.
That being said, I see no way of completely avoiding functions returning values, for now. See functions.
Same as the C++ "this", but it's a reference not a pointer. I find "self" easier to explain to beginners than "this".
Not sure about this yet. In theory, "type" is sufficient, but "struct" clarifies the intent with fewer keystrokes. The two following declarations are identical in meaning:
type ConcreteType $ std.Patterns.PODS interface |<> # Public member variables and subprograms here. struct AnotherConcreteType |<> # Public member variables and subprograms here.
As opposed to C++, a "struct" cannot have a "private" part or "virtual" (latebind) subprograms.
Not much to say here. The rationale for such a mechanism (explained in "The Design and Evolution of C++"), as well as the C++ keywords and underlying mechanisms for templates seem hard to improve upon, except for:
- No more silly "typename" keyword, since you can specify what kind of template parameter should be used with "stric";
- Maybe a bit of syntactic sugar that doesn't cost us anything, since "secondary keywords" don't pollute the global namespace:
- template.instantiate;
- template.specialize;
- no ambiguity with the angle brackets < and >, since bit-shift is now
a
different symbol,
and "greater than" and "less than"
comparaison operators
now look different;
- Because GePSyPL has the notion of a "central compilation authority" (i.e. the compiler knows all the "translation units" and their order of compilation, among others because of the "filemap" and "package" keywords), there is probably an opportunity to reduce code bloat that is biting my leg, even though I can't quite see it yet.
- The "template" feature doesn't have to support "meta-programming", i.e. it would be limited to numbers 1 and 2 in the list of four possible levels of meta-programming given in [Stroustrup 2014], p. 780.
- Etc.
A few initial attempts at syntax:
# A simple template type: template <SomeTemplateParameter $ SomeRestriction> type MyType |> s SomeTemplateParameter # Defining a template subprogram taking two type parameters # (Notice those parameters must conform to interfaces, either "stric" # or "type" interfaces.) template <Toto $ SomeStric anotherStric andAnotherStric, Titi |> SomeType> proc myProcedure[a Toto % b Titi] a.doIt[] b.someMemberVariable = 23232
I love the idea of "design for testing" (also called "test-driven development or TDD", etc.). Not in the sense of "weighing yourself more often will make you skinny" (as Steve McConnell says, testing is not a substitute for building high-quality code). Rather in the sense of testing "Long before, Before, During and After":
- Long Before coding: Starting with the tests before coding some small unit of code
(like a function or a type) is a bit like starting with Use Cases for the whole
system. (You ask yourself: "What is this thing supposed to accomplish? What are the
clients of this chunk of code hoping it will do? What test cases will this code
have to pass?")
- Before coding: if you actually design for testing, if you built it so it will
be testable, bugs will have fewer nooks and crannies to hide in.
- While coding: It's good to start testing earlier in the development process (i.e.
you don't need for the whole product to be built before testing can begin).
- After coding: after the software has been finished, eventually clients ask
for changes (if only to fix bugs). And after each little change, the whole
system should be tested. This is impractical without an automated regression test
suite.
Apparently, many programming languages use some variation of a testing framework composed of a "test runner" executing objects inheriting from "test case" and usually grouped into "test suites" (to facilitate setup and teardown of independant testing contexts): "Following its introduction in Smalltalk the [xUnit] framework was ported to Java [as JUnit] by Kent Beck and Erich Gamma and gained wide popularity, eventually gaining ground in the majority of programming languages in current use." [Wikipedia]
How could this be done in GePSyPL?
- A "test" keyword? GePSyPL loves to add new keywords! But there are other reasons, mostly that a better collaboration between tests and the compiler makes the programmer's life easier.
- Test sections are automatically "#ifdef'ed" out, i.e. all the test code is automatically removed by the preprocessor when testing is disabled. This means the source code and the testing code can be in the same file, simplifying maintenance (and encouraging TDD).
- Only modules can have "test" sections. Testing just one type or just one subprogram doesn't make much sense; you probably want to test a group of types designed to work together. Also, there is by definition no programming in a package, so you can't test almost inexistant programming.
- Because of the existence of the "import.level" section, the IDE would know where all the source code files are, and what is their "levelization", and since each module (normally) would have its "test" section, the IDE could automate regression tests for the whole system (or just part of it). Automatic regression test generation! ;-)
- I'm guessing the "test" section of the "gepsypl" module would be special. That is where "the tests" would be activated. So you could have a "setup[]" and "teardown[]" valid for all test cases (so, for example, you could have an unattended regression test that would just log all results to a file, with no GUI).
- Maybe the "test" section would be a bit "magic", it would slightly change the language, to automatically ignore all "public/protected/private" accessibility specifications? In other words, everything in that module would be "friends" with everybody else". So the test code could play around in the private parts of all types. (Or maybe add another keyword or operator to selectively disable such protections, but only in the "test" section"?)
- Maybe also some kind of automatically-declared simple GUI, which since it was all "ifdef'ed out" when not in test mode, would not shove some fancy windows-and-mouse stuff down everybody's throats (but would make it available in test mode, so you could pop error messages or log them for unattended tests).
- The "import" list of the module would of course be automatically repeated in the "test" section.
- Maybe we could eliminate much of the "OO cruft" of "JUnit" because of this better integration with the compiler. I don't really need "virtual function overrides" of some "TestCase class". I know a module has a test section, so execute the stuff in that test section! Just like the "gepsypl" section doesn't need some complicated "public static void main()" cruft.
- Probably reuse "test.case" keyword, which could be associated with a string (the test case name), so the IDE could: calculate how many test cases there are, and display a progress bar; query the GUI between each test case to see if the user has hit the "Cancel" button; since some kind of "stderr" would be setup before the test suite would be started, the name of each test could be displayed or logged automatically; etc.
- I guess each "test.case" would be automatically placed in its own "try-catch" block. So the IDE could automatically catch unexpected exceptions and log them, and either by default halt the tests or if user specifies, continue the tests and damn the exceptions!
- "test.assert" can automatically take the source code of the actual assertion, and log it as a string (not something a testing framework can do easily).
- Like the "D" language, I have to add some feature to let the programmer select some test cases to be used as sample code, so the sample code is always up to date and working! But otherwise I don't like the "unittest" of "D".
# Imagine this is at the bottom of the "Scanner" module: # (The only remarkable thing going on here, compared to some JUnit # equivalent, is how little code there is, while maintaining all the # features of a full automated regression test suite.) test # Setup const pathTestFiles "(test/scanner/"), extensionTestFiles "(.txt") var token Token, loc ErrorReporter.SourceCodeLocation # Actual series of test cases: case "(Completely empty file") var file File[pathTestFiles + case.name + extensionTestFiles] Scanner.getToken[file % token loc] assert token '= Token.TokenCode.EOF case "(Lots of pure whitespace") var file File[pathTestFiles + case.name + extensionTestFiles] Scanner.getToken[file % token loc] assert token '= Token.TokenCode.EOF # Teardown
Not much to say here. The rationale for such a mechanism (explained in "The Design and Evolution of C++"), as well as the C++ keywords and underlying mechanisms for exceptions seem hard to improve upon, except for:
- all exceptions should derive from the same exception base class, like Java
and Swift, etc.
- I find "throw specifications" and complex exception hierarchies a contradiction in
terms. A "throw specification" implies you know what error will occur in that
subprogram (or in any number of subprograms called by it). But if you know exactly
what errors are going to happen in exactly which subprograms, then they are not
"exceptional" occurences anymore. An "exception hierarchy" implies exceptions (i.e.
errors) have definite natures. But "error" by definition is not something
clearly defined. As Aristotle explains, there is only one way to build a chair
properly, but an infinite number of ways to build a chair incorrectly. Error is
infinite, and formless.
- I would prefer "catch default" to the C++ "catch(...)" syntax, among others
because the word "default" is
intentionally common
in GePSyPL.
The equivalent of "unsafe" in other programming languages. I prefer "trust me" to "unsafe", because if that source code is dangerous, it should not be allowed. But if the programmer really knows what he is doing, and this low-level trick is required for hardware-specific reasons, then the compiler has to trust the programmer.
It's mostly a tool for managers, who can more easily enforce things like: "Only senior programmers like Bob may use that keyword and other low-level facilities of the language".
Offhand, I'd say only "module"s and the "gepsypl" main program can have the property of being "trusted", so the "trustme" keyword would be right up there at the top, and it would "contaminate" the whole file. In other words, it would encourage programmers to put all the low-level and dangerous stuff in specific modules, not scattered all over the place if the "trustme" keyword had been a property of a subprogram.
For code samples, see goto, raw pointers, etc.
Roughly the same thing as the C++ "auto". Greatly simplifies parsing also. Sometimes "var" is implicit, like after "foreach" (to declare the variable that will represent each element of the container, one after the other), and perhaps also after "type", if we decide not to use the UML "strong ownership" symbol, in order to declare member variables for that type.
I'm not sure yet, but maybe make it more explicit where the memory is being taken to produce a variable?
# Define an variable called "i", with memory taken on the stack, of type # "integer" (this is deduced from the initial value), and with initial value # of zero. # (Note this is the most frequent case, so it's also the most terse.) var boringInteger 0 # Same thing, but painfully explicit: var.stack belabourTheObviousInt int.ctor[0] # Now the memory is taken from the "program text", i.e. the # memory for this variable is allocated when the program is loaded into # the main memory, and will "live" or be available for the whole duration # of the program execution: var.static fortranRocks 1957 # Now the memory is taken from the "heap" (i.e. # "dynamically-allocated"). WARNING! "onTheHeap" is what C++ calls a "unique_ptr"! # (a "smart" pointer that will remember to deallocate the memory for you). var.heap onTheHeap -82827 # Here, the memory is again taken from the "heap", but no "smart pointer" # (i.e. you need to be in a "trustme" module, and you'd better know what # you're doing, not only because you're getting a raw pointer, but also # the memory is uninitialized. Note also the intentionally ugly and verbose # syntax.) var.heap shootOffYourFoot @byte[compiler.sizeof[int]]
I toyed with the idea of also having "var.global" just to help teach young programmers (especially to avoid global variables).
# Let's count to 10: gepsypl var counter 1 while counter '< 11 screen counter "( ") ++counter
Identifiers are case-sensitive. For example, "Hello", "hello" and "hEllo" are three different identifiers.
I started out by saying:
Keywords are case insensitive for the scanner, but must be lowercase. In other words, "Var", "gepsYpl" and "iF" are all keywords (not identifiers), and will cause a compiler error because keywords must be all lowercase.
But this imposes an expensive "toLower[]" operation on every string that is read by the Scanner, just in case it might be a very rare identifier with one or more uppercase letters... So I changed that rule to be like C++: keywords are all lowercase, so if something contains one or more uppercase letters, it cannot be a keyword.
Many operators are digraphs or trigraphs (or worst!). Why not just use Unicode?
First, in order to be usable on average computers used by average-income programmers, I decided to use the ASCII code, which is very limited (but almost universally available). This of course doesn't prevent anybody from using Unicode to program, but the language itself doesn't require it.
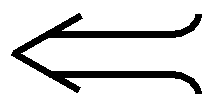
Second, I'm not even sure Unicode, with its over one million glyphs, even has the symbols I'd like. Assignment for example might be nicer if we combined the visual metaphors of "injection from one side into the other" and "subsequent equality", like this:
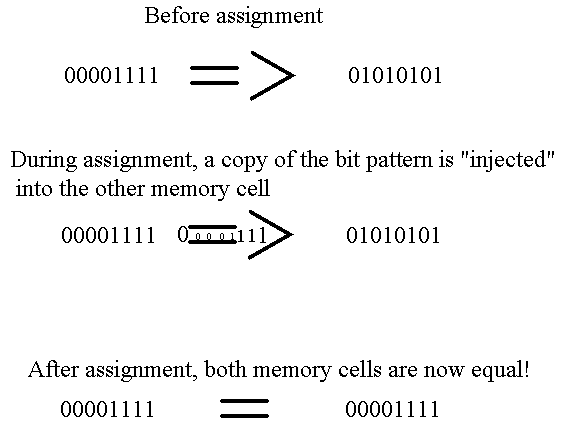
The available Unicode glyph seems to be U+2190 (left arrow, if it displays properly on your computer, because it doesn't on mine: ࢎ), but it's not as visually rich as this, for example:
Instead of the ugly and insignificant "bit" symbol, I'd love to have something that better represents "a single unit of information, either true or false, black or white, 0 or 1", but I'm not sure Unicode has something like this:
My third argument is the one I think is the strongest, but I would need a lot of time to explain myself. I think we need RomaCode (or some equivalent).
There already is a kind of "countdown to machine-code", starting with the source code (the GePSyPL program as such), then "object" code (i.e. what traditional compilers produce, but which could also be "jittable" bytecode or some other IR or Intermediate Representation), then the actual executable file with all parts properly linked together.
Ideally, we would also have other choices, like "components" that would be one large physical file, but that would internally contain:
- The actual programming product (hopefully some IR that could then be linked and
adapted to several platforms, but not easily reverse-engineered).
- The equivalent of the C++ ".h" files necessary to use them.
- A help file for the programmer.
- some kind of "descriptor" so the component could integrate itself with a
"Delphi-like" RAD IDE (Rapid Application Development, Integrated Development
Environment).
- If this software component had external dependencies, then a full description
of those dependencies. (I hate having a piece of software in my hands, then
finding out it's useless because some mysterious DLL is missing... At least put
a big orange sticker on the box saying "Batteries NOT included!", and a description
of the number and precise model of batteries required!)
I don't know if it's a good idea, but on Windows-type environments, maybe the file extensions could reflect that "countdown to machine-code", so ".gy7" would be the source code, etc. (I was leaving unused numbers for a bit of forward compatibility. Also, the silly ".gy" is chosen mostly because it seems to be unused, and can be pronounced "Gee" as in the letter "G" for GePSyPL.)
Source code files may not start with spaces or newlines (it just causes a compilation error). The reason is to simplify the scanner. It is a very minor restriction on the programmer's freedom, and accelerates the compilation.
"Indentation rules" are basically the same as Python, with a few minor changes. For example, to conserve screen width, I think some keywords will automatically trigger an "indentation reset", for example export, so what follows, even if not indented, will still be considered part of the module or package.